
Convy Data Collection
Practice
During this quarantine period I've been spending some time revisiting machine learning practice. As is ML protocol, I've started with CNNs.
CNN: Convolutional Neural Network- Neural network architecture that provides good results on image classifcation tasks.
I've now trained several networks for all the usual image recognition starter datasets (MNIST, MNIST fashion, CelebFace 3-4 different features, your typical cat/dog dataset) beginning with transfer learning and then attempting to get within 10% accuracy of those results on a custom trained net (thank you Google Colab for your free GPUs).
A teacher of mine once described the practice of machine learning with the iceberg metaphor: designing and creating the network architecture is ~15% of the work and yields a proportional amount of the end quality; the other 85% is informed data collection and processing.

Implementation
I decided I should try my hand at the data collection and processing pipeline portion of the ML workflow. I wanted to solve the vital problem of using ML to classify my parent's cats Arlo and Lola.

iOS App
To get some Swift training, I decided to build the following iOS app. It was built in ~5 hours and used Firebase as a backend to minimize the amount of time spent on backend config.
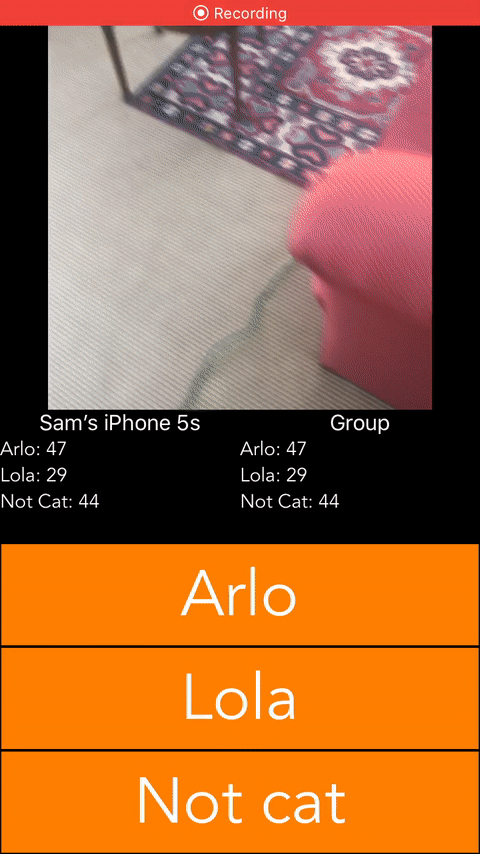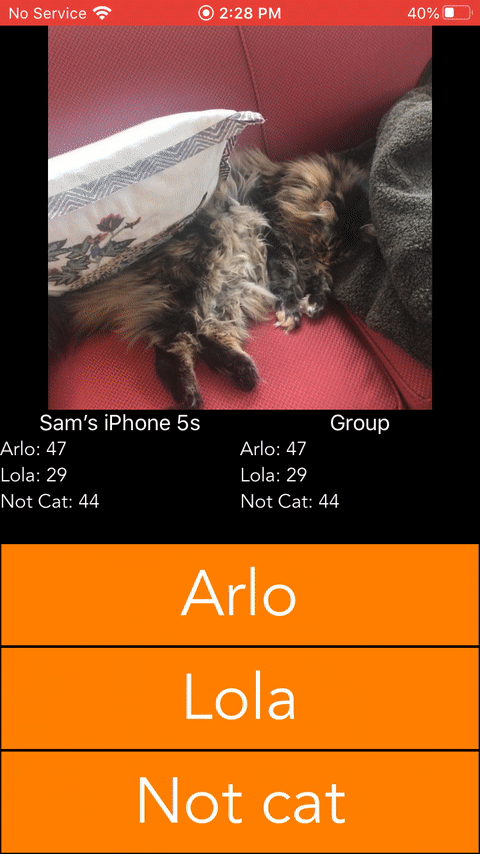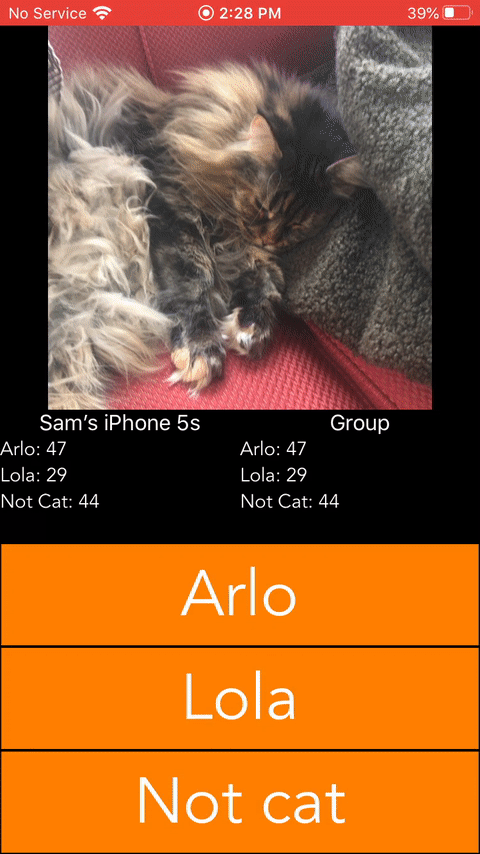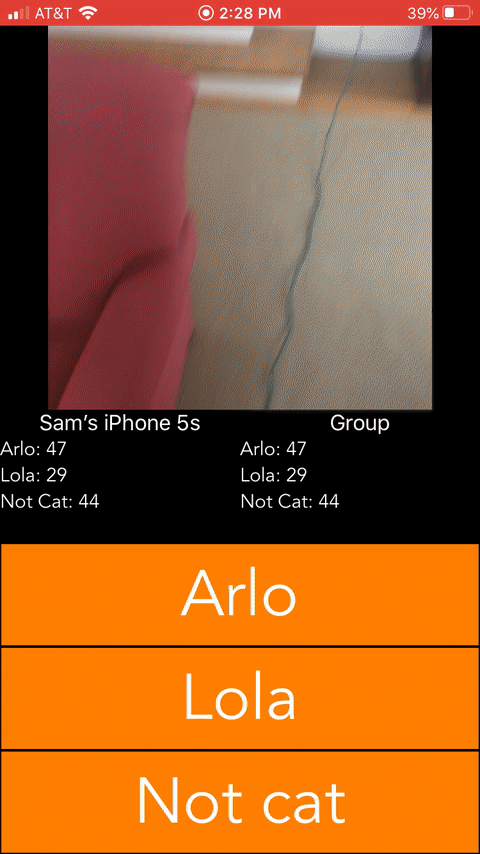
Conclusions
Training dramatically overfit. I stopped collecting data around ~1500 images/cat. I got bored. I attempted to enlist the help of my family, who were happy to be of service, but it was hard to explain what "good" images were for training a Convy, resulting in excessive data janitorial services.
My main takeaway from this effort was that closely correlated images (taking in rapid succession) do not make for a good training set. It is infact true that 85% of the work of training a convy is informed data collection and processing.